Abstract Link to heading
Composed video retrieval (CoVR) is a challenging problem in computer vision which has recently highlighted the integration of modification text with visual queries for more sophisticated video search in large databases. Existing works predominantly rely on visual queries combined with modification text to distinguish relevant videos. However, such a strategy struggles to fully preserve the rich query-specific context in retrieved target videos and only represents the target video using visual embedding. We introduce a novel CoVR framework that leverages detailed language descriptions to explicitly encode query-specific contextual information and learns discriminative embeddings of vision only, text only and vision-text for better alignment to accurately retrieve matched target videos. Our proposed framework can be flexibly employed for both composed video (CoVR) and image (CoIR) retrieval tasks. Experiments on three datasets show that our approach obtains state-of-the-art performance for both CovR and zero-shot CoIR tasks, achieving gains as high as around 7% in terms of recall@K=1 score
Introduction Link to heading
Introduction Composed image retrieval (CoIR) is the task of retrieving matching images, given a query composed of an image along with natural language description (text). Compared to the classical problem of content-based image retrieval that utilizes a single (visual) modality, composed image retrieval (CoIR) uses multi-modal information (query comprising image and text) that aids in alleviating miss-interpretations by incorporating user’s intent specified in the form of language descriptions.
The problem of CoVR poses two unique challenges: a) bridging the domain gap between the input query and the modification text, and b) simultaneously aligning the multimodal feature embedding with the feature embedding of the target videos that are inherently dynamic. Further, their context can also vary across different video frames.
To addres the problem of CoVR, the recent work introduces an annotation pipeline to generate video-text-video triplets from existing video-caption datasets. The curated triplets contain the source and target video along with the change text describing the differences between the two videos.
We note that the aforementioned framework struggles since the latent embedding of a query visual input (image/video) is likely to be insufficient to provide necessary semantic details about the query image/video due to the following reasons: a) visual inputs are high-dimensional and offer details, most of which are not related to the given context, b) the visual depiction often shows a part of the broader context and there exist non-visual contextual cues that play a crucial role in understanding the given inputs.

Contributions: We propose a framework that explicitly leverages detailed language descriptions to preserve the query-specific contextual information, thereby reducing the domain gap with respect to the change text for CoVR.
- we utilize recent multi-modal conversational model to generate detailed textual descriptions which are then used during the training to complement the query videos.
- we learn discriminative embeddings of vision, text and vision-text during contrastive training to align the composed input query and change text with target semantics for enhanced CoVR.
Related Work Link to heading
Composed Image Retrieval (CoIR) Link to heading
The problem holds extensive practical significance finding applications in diverse domains such as, product search, face recognition, and image geolocalization.
CoIR is challenging since it requires image retrieval based on its reference image and corresponding relative change text. Most existing CoIR approaches are built on top of CLIP and learn the multi-model embeddings comprising reference image and relative change text caption for target image retrieval.
These methods carefully harness the capabilities of large-scale pretrained image and text encoders, effectively amalgamating compositional image and text features to achieve improved performance
Composed Video Retrieval (CoVR) Link to heading
Early efforts in this domain predominantly explored content-based retrieval approaches, leveraging key-frame analysis, color histograms, and local feature matching. The advent of deep learning techniques has further revolutionized text-to-video retrieval, with the emergence of multi-modal embeddings and attention mechanisms.
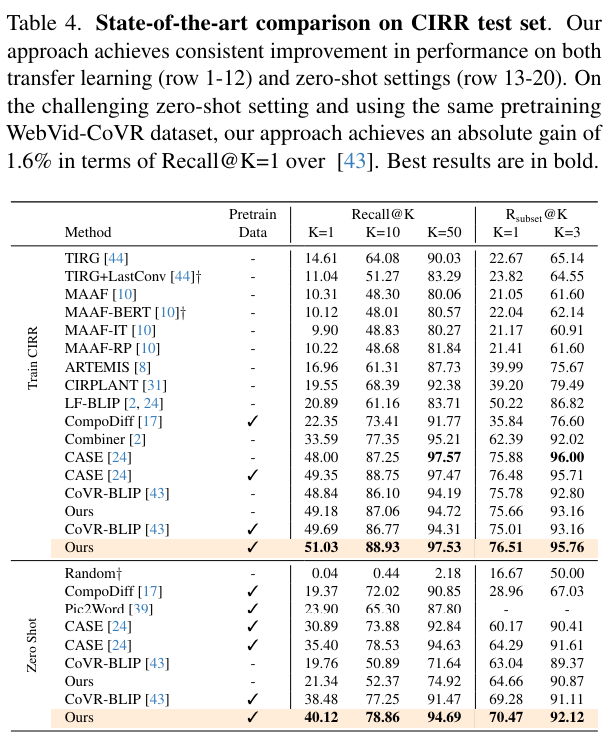
Recently, a study explored the problem of composed video retrieval (CoVR) where the objective is to retrieve the target video, given the reference video and its corresponding compositional change text. It also proposes a new benchmark for CoVR, named WebVid-CoVR, which comprises a synthetic training set and a manually curated test set. Further, the authors also propose a framework, named CoVR-BLIP, that is built on top of BLIP where an image grounded text encoder is utilized to generate multi-model features and aligns it with target video embeddings using a contrastive loss.
Our Approach Link to heading
Different from CoVR-BLIP, our approach leverages detailed language descriptions of the reference video that are automatically generated through a multimodal conversation model and provide with following advantages.
- It helps in preserving the query-specific contextual information and aids in reducing the domain gap with the change text.
- Rather than relying on only using the visual embedding to represent target video as in, learning discriminative embeddings through vision, text, and vision-text enables improved alignment due to the extracting complementary target video representations.
Method Link to heading
Problem Statement Link to heading
Composed Video Retrieval (CoVR) strives to retrieve a target video from a database. This target video is desired to be aligned with the visual cues from a query video but with the characteristics of the desired change represented by the text.
Formally, for a given embedding of input query \(q \in Q\) and the desired modification text \(t \in T\), we optimize for a multi-modal encoder \(f\) and a visual encoder \(g\), such that \(f(q, t) \approx g(v)\), where \(v \in V\) is the target video from a database.
Baseline Framework Link to heading
To address the above problem, we base our method on the recently introduced framework, named CoVR-BLIP, that trains the multi-modal encoder \(f\) which takes the representations from the visual encoder \(g\).
The visual encoder \(g\) remains frozen and is used to get the latent embeddings for visual input query which are then provided to multi-modal encoder \(f\) along with the tokenized change text $t$ to produce multi-modal embedding \(f(q, t)\). Then, the input visual query and the change text $t$ are aligned with the desired target videos using a contrastive loss between \(f(q, t)\) and \(g(v)\).
Architecture Design Link to heading
Motivation. To motivate our proposed approach, we distinguish two desirable characteristics that are to be considered when designing an approach for the CoVR task.
We argue that such a query-specific contextual information can be incorporated in the image-grounded text encoder through detailed language descriptions of these query videos.
Therefore, the correspondence between embedding of the visual input \((q)\) and its corresponding detailed description \((d)\) results in an enhanced vision-text representation \(f(q, d)\) of \(q\), thereby ensuring a contextualized understanding of the query video.
Further, the complementary nature of detailed descriptions aids in reducing the domain gap between the input query and the modification text by establishing correspondence between the detailed description of the input query and the modification text, as \(f(d, t)\).
$$ v^*=\underset{v \in V}{\arg \max } \quad \mathcal{L}(\tilde{f}(q, d, t), g(v)), \tag{1} $$$$ \tilde{f}(q, d, t)=f(q, t)+f(q, d)+f(e(d), t). \tag{2} $$where, $q$ and $d$ represent input query (image/video) and its corresponding language description, t is the desired modification text, \(\tilde{f}(q, d, t)\) is the pairwise summation of individual correspondence embeddings and \(\mathcal{L}\) is a similarity-based loss.
Learning Discriminative Embeddings for Alignment. In the CoVR task, the model is desired to learn to align its output with the target video after mixing the change text with the query video. Instead of only representing the target video in the latent space through a visual embedding, a multiple discriminative embedding of vision, text, and vision-text is expected to provide better alignment due to complementary target video representation.
Overall Architecture. The proposed architecture comprising three inputs: the reference video, the text corresponding to the change, and the detailed video description. Compared to the baseline framework, the focus of our design is to effectively align the joint multi-modal embedding, comprised of the three inputs (\(\tilde{f}(q, d, t)\)), with the target video database to achieve enhanced contextual understanding during training for composed video retrieval.
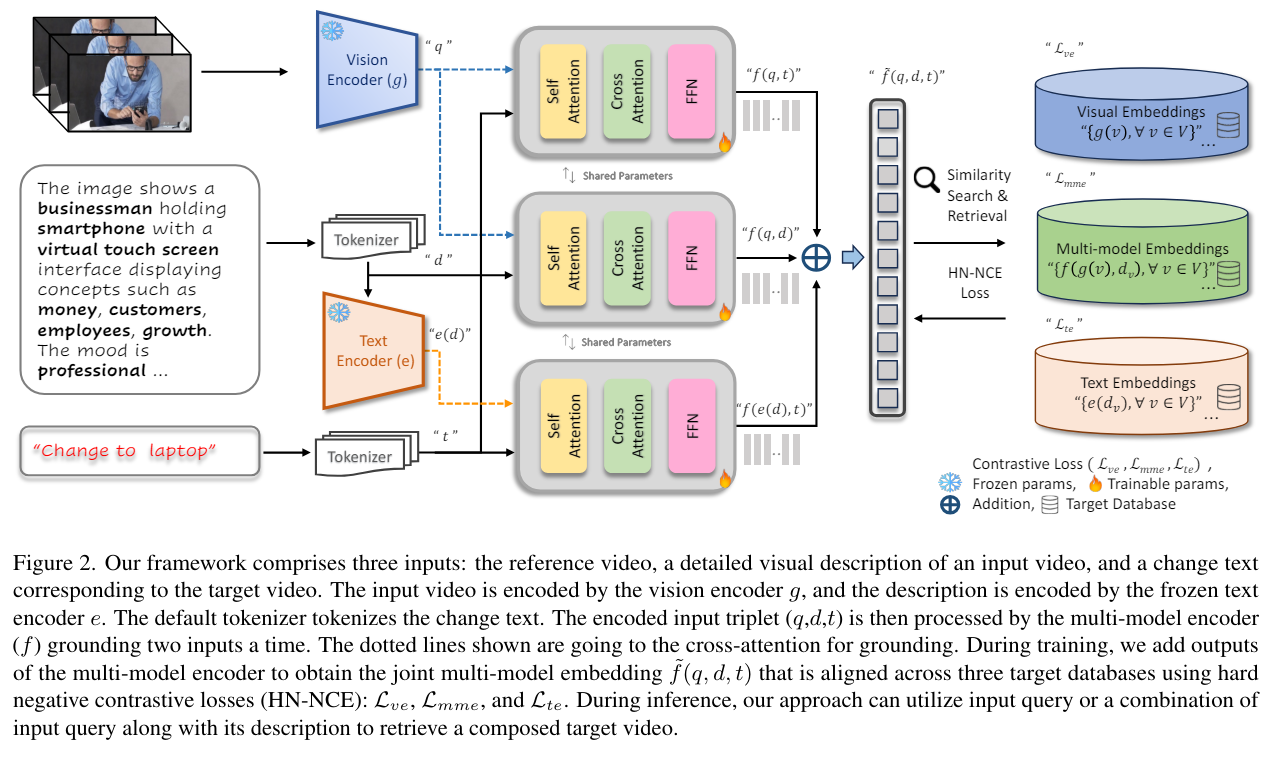
We first process the reference video and its description using pre-trained image encoder \(g\) and text encoder \(e\) to produce their latent embedding of the same dimension as, \(q \in \mathbb{R}^{m}\) and \(d \in \mathbb{R}^{m}\).
The multi-modal encoder \(f\) takes the visual embeddings from a pre-trained visual encoder \(g\) along with tokenized textual inputs and produces a multi-modal embedding. Given the tokenized change text \(t\), and embeddings of the reference video and its descriptions, \(q\) and \(d\), we fuse any two inputs at a time using the multi-modal encoder \(f\) comprising of crossattention layers, to produce joint multi-modal embeddings (\(\tilde{f}(q, d, t)\)).
Within the proposed framework, we only train the multimodal encoder \(f\) whereas the image and text encoders remain frozen. During training, we provide the change text \(t\) and the visual query embeddings \(q\) to the encoder \(f\) for obtaining the multi-model embeddings \(f(q, t)\) corresponding to the change text \(t\).
We combine these grounded embeddings in a pairwise summation manner to obtain the joint multi-model embeddings \(\tilde{f}(q, d, t)\). These joint multimodel mbeddings are then utilized to retrieve the target video from the database.
$$ \begin{aligned} \mathcal{L}= & -\sum_{i \in \mathcal{B}} \log \left(\frac{e^{S_{i, i} / \tau}}{\alpha \cdot e^{S_{i, i} / \tau}+\sum_{j \neq i} e^{S_{i, j} / \tau} w_{i, j}}\right) -\sum_{i \in \mathcal{B}} \log \left(\frac{e^{S_{i, i} / \tau}}{\alpha \cdot e^{S_{i, i} / \tau}+\sum_{j \neq i} e^{S_{j, i} / \tau} w_{j, i}}\right) \end{aligned} $$Query-specific Language Descriptions Link to heading
In order to obtain the video descriptions, we employ a recent open-source multi-modal conversation model. Generally, multi-modal conversation models learn alignment between a pretrained large language model such as, Vicunna and a pretrained vision encoder of vision language model such as, CLIP or BLIP.
Since these are image models and for our case of video inputs, we sample the middle frame of the video and generate its detailed description using a multi-modal conversation model by prompting the model with “Describe the input image in detail”. We further remove the noise within these descriptions by removing the manually curated unnecessary symbols, tokens, or special characters. Further, these models can hallucinate about a given visual sample.
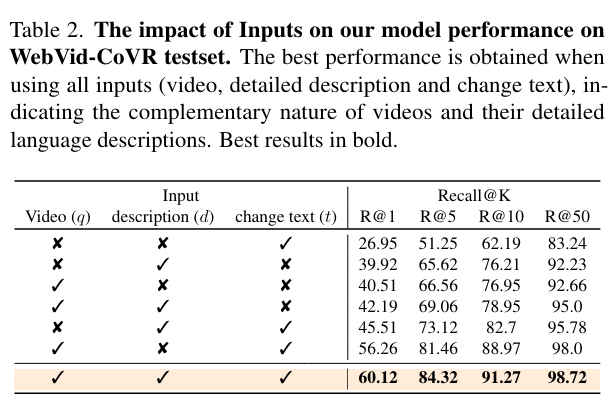
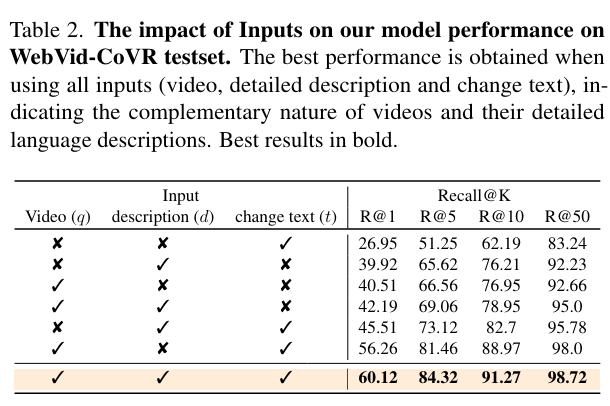
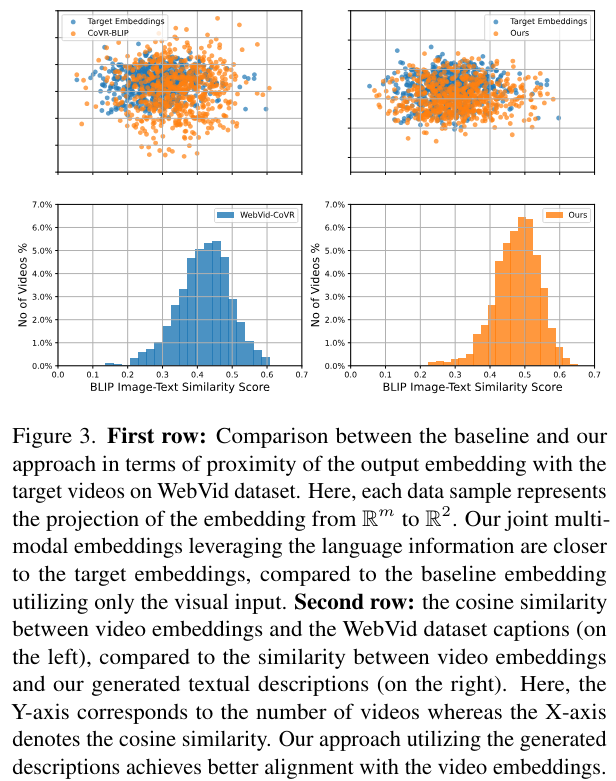
To identify hallucinated descriptions, we first measure the lower bound of cosine similarity between default WebVid captions and visual inputs within BLIP latent space to identify a hallucination threshold. We then discard those descriptions, where the cosine similarity between our generated description and the visual input is lower than the hallucination threshold. Consequently, the resulting enriched descriptions are better aligned with the videos (Fig. 3). As discussed earlier, the base framework only aligns the input video with the target video database.
Enhancing Diversity in Target Database Link to heading
The proposed method takes three inputs (video, modification text, and video description) and three target databases to train the model.
- The first target database is based on the visual embedding of input videos generated by a pretrained vision encoder of BLIP-2.
- The second target database is based on multi-model embeddings derived from the pretrained multi-modal encoder of BLIP-2.
- The final target database is based on a text-only embedding of the video description generated by the pretrained BLIP-2 text encoder.
We use these additional databases only during training time to compute the hard negative contrastive loss between our joint multi-model embeddings and target datasets
Overall Loss Formulation Link to heading
For a given batch B, we formulate hard negative contrastive loss for each of our three target databases
$$ \mathcal{L}_{\text {contr }}=\lambda * \mathcal{L}_{v e}+\mu * \mathcal{L}_{m m e}+\delta * \mathcal{L}_{t e}, \tag{4} $$where, \(\mathcal{L}_{v e}\), \(\mathcal{L}_{m m e}\), and \(\mathcal{L}_{t e}\) are the contrastive loss represented by Eq. (3). We compute the similarity of \(\tilde{f}(q_i, d_i, t_i)\) with the corresponding target video embedding \(g(v_i)\), target multi-modal embedding \(f(g(v_i), d_{vi})\), and the target text embedding \(d_{vi}\) for \(\mathcal{L}_{v e}\), \(\mathcal{L}_{m m e}\), and \(\mathcal{L}_{t e}\), respectively. \(\lambda\), \(\mu\), and \(\sigma\) are learnable parameters that scale the weightage of each loss during training.
Inference Link to heading
During inference, for the 3 given inputs: reference video, description and change text, we first process the reference video and its description using pre-trained frozen image encoder $g$ and text encoder $e$ to produce their latent embedding. The change text is simply tokenized as shown in Figure 2. We use the multi-modal encoder $f$ and gather the multi-model embeddings from 2 inputs at a time such as \(f(q, t)\), \(f(q, d)\) and \(f(e(d), t)\). Consequently, we simply do the pairwise addition of three (3) multi-model embeddings to produce joint multi-modal embeddings \(\tilde{f}(q, d, t)\) for target video retrieval.
Experiments Link to heading
Experimental Setup Link to heading
Dataset Link to heading
We evaluate our approach on the recently introduced WebVid-CoVR dataset. The training set of WebVid-CoVR consists of triplets (input video, change text, and target video) and is generated synthetically, whereas the test set is manually curated using the model in the loop.
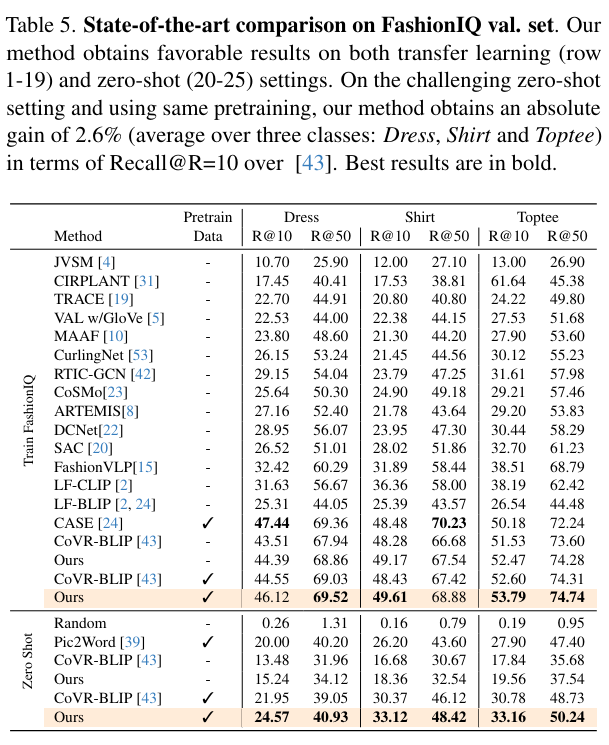
We use CIRR and FashionIQ benchmarks for composed image retrieval. CIRR consists of manually annotated open-domain natural image and change text pairs with (36.5K, 19K) distinct pairs.
Evaluation Metrics Link to heading
We follow standard evaluation protocol for the composed image as well video retrieval from We report the retrieval results using recall values at rank 1, 5, 10, 50. Recall at rank \(k\) (\(R@k\)) denotes the number of times the correct retrieval occurred among the top-\(k\) results